







Scattered among computers and hard drives across state, provincial and international borders is a treasure trove of information detailing the flight paths of traveling shorebirds. Although the number of birds carrying small satellite tracking backpacks has increased, the data is often inaccessible to people on the ground who may not be aware a tracked shorebird traveled near them.
Accessing and using shorebird tracking data has struggled to keep up with data collection because the data demand specialized expertise to answer conservation questions. Autumn-Lynn Harrison, a research ecologist at Smithsonian’s National Zoo and Conservation Biology Institute, and her collaborators published a study recently in Conservation Biology describing their work. They discussed how they took millions of observations, scattered across institutions; combined them into a centralized resource; and developed ways to more quickly deliver insights from these complex movement data to conservation practitioners.

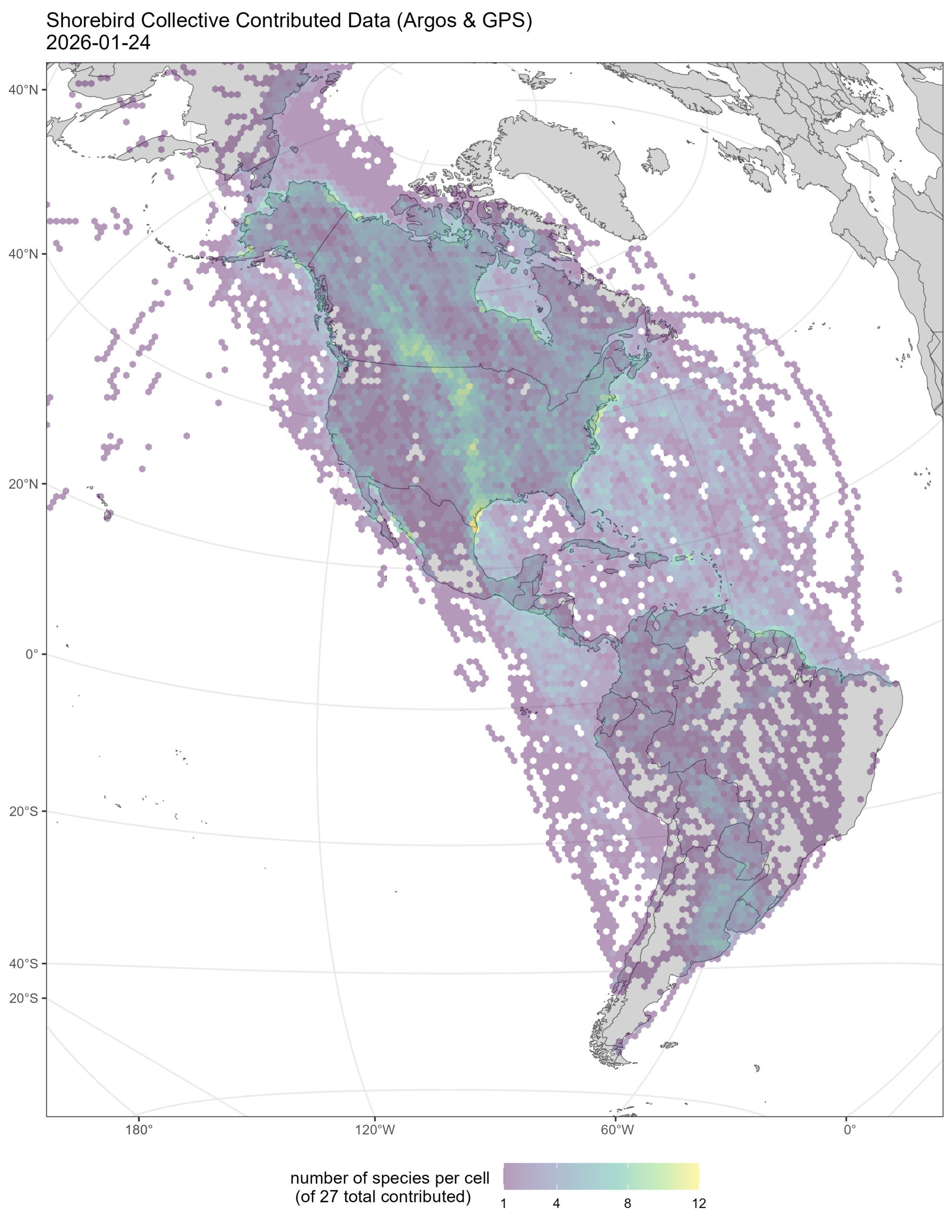
Harrison founded the Shorebird Science and Conservation Collective, an initiative that translates the combined findings of shorebird tracking data into on-the-ground conservation action. The Collective has received data contributions from 87 organizations, including over 10.2 million shorebird observations that form movement paths for 3,998 individuals representing 38 species tracked across the Americas. With this data, they have informed over 50 conservation projects.
For our latest Q&A, The Wildlife Society caught up with Harrison to discuss the challenges of turning shorebird tracking data into actionable conservation and how the Shorebird Science and Conservation Collective is working to narrow the gap.
What inspired this work?
I’ve been doing animal tracking work for about 20 years, uncovering previously unknown migrations and collaborating with many partners. You always hope that science reaches decision-makers, but especially for shorebirds, much of the work is new and takes years to get published and into managers’ hands. Co-author Paul Smith’s work shows that over 50% of monitored North American shorebird populations have declined by over 50% since 1980, and the science is needed for conservation now. I realized practitioners aren’t usually going to have time to find 20 datasets, email 20 scientists and analyze the data themselves. It’s just too slow. So, I started thinking about creating a kind of “matchmaking service” to connect science directly with conservation questions and make that process as frictionless as possible.
How have advances in tracking technology changed the field, and why does working with that data remain so complex?
When I started, I worked with large animals like seals using large tracking tags. Back then, processing the data was difficult because the code wasn’t really available for the public to use for it yet. There weren’t user-friendly tools; it was just complicated software, and it took a lot of work to even process the data.
So, I’ve seen two major advances. Firstly, satellite tags got much smaller, opening up many research avenues. Secondly, the ability to process data and handle errors, irregular sampling and other data collection methods that make ecological data messy is now standardized. There are shared code libraries to handle it.

But the data are still messy. We’re often bringing together data collected with multiple technologies over time and from different manufacturers. We have some tracking devices that may collect only one position per day, while others may collect 20 positions or more per day. Trying to integrate those into a statistical system for conservation insights can be tricky.
The other sampling messiness we see a lot is if a tag does not always collect data on the schedule that you want. A hurricane might come through, and the tag goes offline for a couple of weeks. Dealing with data gaps and understanding when you can make inferences across them, when you can’t and when you would be stretching beyond what the data say makes it complicated.
At the Shorebird Science and Conservation Collective, we aren’t simply a data repository; we’re also serving as data interpreters to inform conservation.
Why has the Collective been successful?
We took a thoughtful approach to setting up the data-sharing agreement and introducing the idea to the community.
I developed the idea for a shorebird collective with Rick Lanctot, of the U.S. Fish and Wildlife Service (USFWS). He’s now the chair of our advisory group. Before we even submitted our funding proposal, we had a webinar with everyone we knew who tracked birds. We talked through the idea with them and asked questions about what they would be comfortable with and what level of data sharing they would want. Many people advised us to make the simplest possible data-sharing agreement that would allow us to use the data liberally without further permissions. This would certainly help reduce our administrative load, but we ignored that advice, and we ended up making it quite customizable.
We have developed solutions that could inform the conservation request while still addressing the owner’s concerns. That takes a lot of time and thoughtfulness. It is not just saying we want all your data; you have to be comfortable with what we want to do with it. We meet people where they are in terms of comfort level with data sharing. Some people were not yet comfortable with making their data fully open access. This was often for important reasons, because a student’s dissertation was still in progress or the data involved an endangered species. However, these researchers still wanted to share their data for conservation purposes. To facilitate this, we gave them the option to approve requests individually through the data agreement. If someone’s not quite ready to share all their data yet, that’s totally cool. There’s no judgment, you know? Sometimes we’ll make a derived product like a simplified map or an infographic, so we don’t have to show the bird’s exact movement path.
So far, 93% of data sharing requests have been approved. I also really wanted a process that could report back to the data contributors. They get a report back each time their data is used. They can put how many requests that their data informed on their CV or funding applications.
Recently, we supported a species status assessment in Canada. These committees work quickly; they must because they only last a year or two. They typically would have had to contact 20 different data owners to get that data. We were able to aggregate the data, produce maps and connectivity analyses, and answer questions such as “Should we list parts of the population as endangered separately?” It’s really exciting because that’s important national-level policy.
Article by Kaylyn Zipp

